Deep learning techniques, especially convolutional neural networks (CNN), have pervaded vision applications across image classification, face recognition, video processing, and so on due to the high degree of accuracy they provide. Both industry and academia are exploring specialized hardware accelerator ASICs as a solution to provide low-latency and high-throughput for CNN workloads.
The convolution operation is a deeply nested multiply-accumulate loop. For throughput and energy efficiency, each accelerator chooses different strategies to manipulate the loop order/tiling of the convolution operations and the spatial/temporal mapping of data on compute units, which we collectively refer to as dataflow. The throughput and energy efficiency of a dataflow changes dramatically depending on both the DNN topology (i.e., layer shapes and sizes), and accelerator hardware resources (buffer size, and network-on-chip (NoC) bandwidth). This demonstrates the importance of dataflow as a first-order consideration for deep learning accelerator ASICs, both at design-time when hardware resources (buffers and interconnects) are being allocated on-chip, and compile-time when different layers need to be optimally mapped for high utilization and energy-efficiency.
We present MAESTRO (Modeling Accelerator Efficiency via Spatio-Temporal Resource Occupancy), an open-source tool for modeling and evaluating the performance and energy-efficiency of different dataflows.
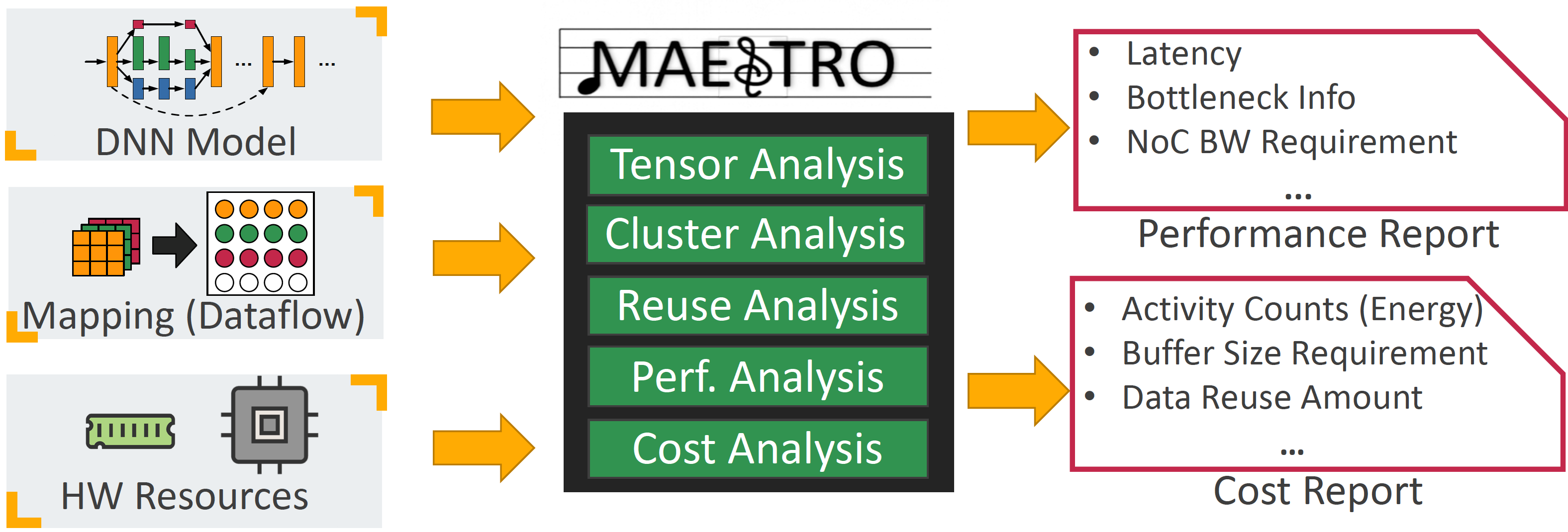
The MAESTRO cost model provides rapid estimation of the performance/energy given a DNN Model, Mapping, HW configuration. It can be used for HW-SW co-design by porting it into tools that perform design-space exploration.
Examples:
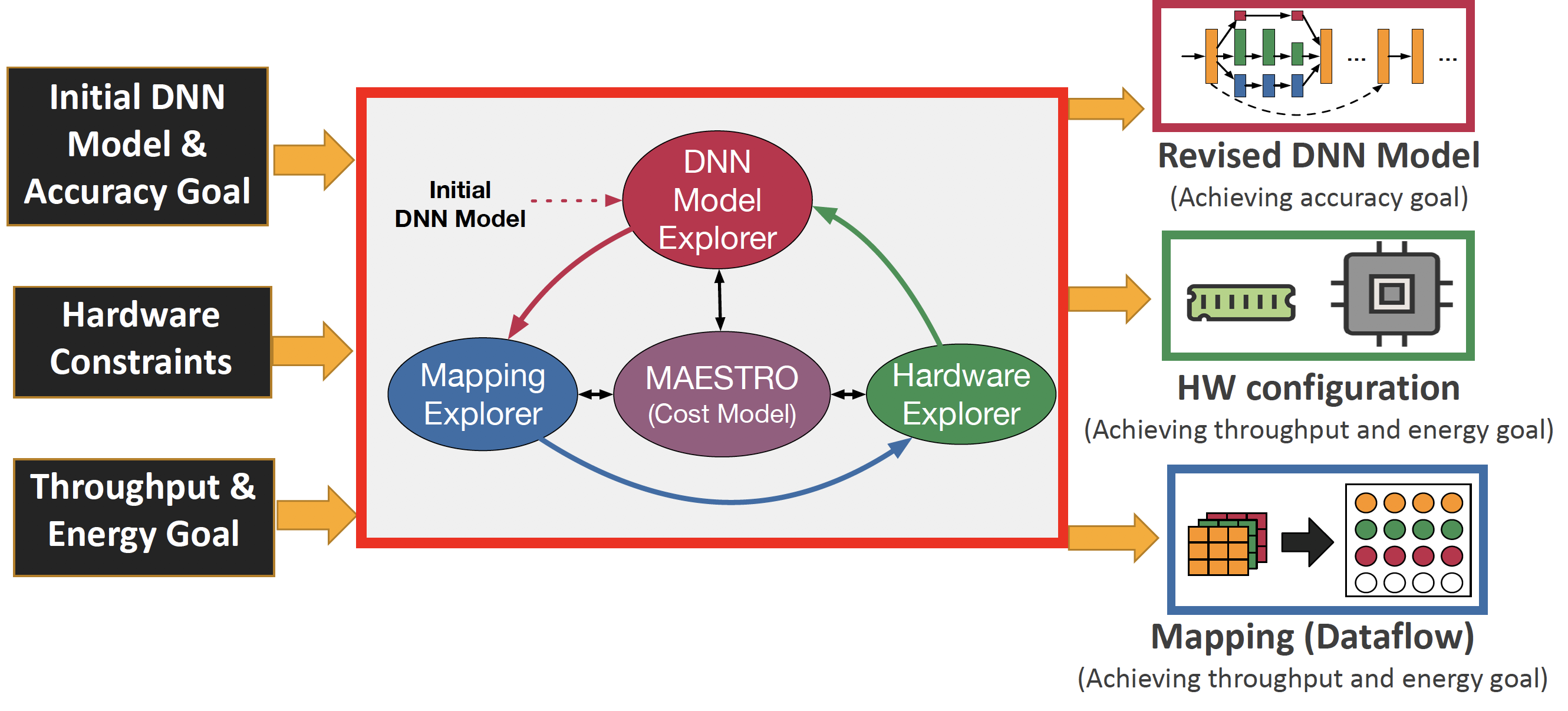
There is plenty of cost data that MAESTRO provides.
Explore what kinds of results will be provided by running MAESTRO! For more details, please visit the following page.